
KI für Laien
Wir gehen davon aus, dass man kein KI-Experte sein muss, um Überlegungen zu Einsatzmöglichkeiten von KI für das Ideenmanagement anstellen zu können – dass es aber hilfreich ist, zumindest einige Grundbegriffe und -prinzipien zu kennen. In diesem Sinne versuchen wir uns in diesem Abschnitt an einer kurzen Einführung von „KI für Laien“ …
Künstliche Intelligenz (KI) „besteht“ aus „Rechenprogrammen“, mit denen menschliche Intelligenz simuliert wird. Was die eigentliche „Intelligenz“ von KI dabei ausmacht, ist die Fähigkeit zu „Lernen“ (meist an bekannten Beispielen) und das Gelernte dann in neuen, bisher unbekannten Situationen anzuwenden: Das geschieht beim sogenannten „Machine Learning“ (Hinweis: Der Begriff „Maschine“ bezeichnet hier alle technischen Geräte, inkl. IT-Hard- und Software).
- Je nach Anwendung müssen noch mehr Fähigkeiten hinzukommen, die zwar nicht zum Kernbereich „künstlicher Intelligenz“ gehören, aber benötigt werden, damit sich KI im Hinblick auf die jeweiligen Aufgabenstellungen „intelligent“ verhalten kann – etwa Fähigkeiten, Wissen in Sinnstrukturen erfassen zu können oder Sprache zu beherrschen (Textverstehen), was besonders im Zusammenspiel mit Menschen wichtig ist.
- Sensorik und Robotik sind Beispiele für weitere mögliche ergänzende Kompetenzfelder, mit deren Hilfe KI das äußere Umfeld wahrnehmen oder auf es einwirken kann.
- Während die grundlegenden Konzepte für KI bereits seit über 30 Jahren bekannt sind, beruht der Boom der letzten Jahre vor allem auf dem Anstieg von Rechnerleistungen, dem Anwachsen der verfügbaren Datenmengen und der zunehmenden Verfügbarkeit von Algorithmen, mit denen diese Datenmengen verarbeitet werden können.
Zunächst zum „Kern von KI“
Die „Lernfähigkeit“ von KI beruht vor allem darauf, mit mathematischen Verfahren „künstliche neuronale Netze“ zu gestalten – also das Zusammenspiel der Gehirnzellen und die Arbeitsweise des Gehirns maschinell zu simulieren (siehe Abbildungen 1-2). Künstliche neuronale Netze „lernen“ dadurch, dass die in den Berechnungsformeln verwendeten Parameter verändert werden. Diese Änderungen werden auf der Grundlage von eingegebenen Daten und vorgegebenen Regeln vom Rechenprogramm selbst vorgenommen.
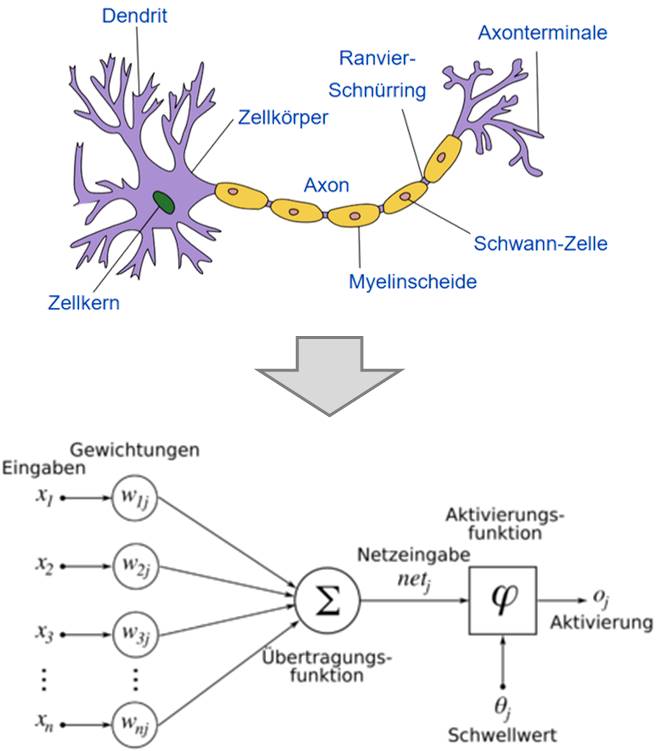
Abbildung 1: Gehirnzellen („Neuronen“) empfangen über sogenannte „Dendriten“ Input von vielen anderen Neuronen. Je nachdem, wie sich dieser Input summiert, bilden sie ein „Aktionspotential“ und geben es als Output über sogenannte „Axonterminale“ an andere Neuronen weiter. Dieses Verhalten lässt sich mit mathematischen Funktionen beschreiben, etwa einer Übertragungs- und einer Aktivierungsfunktion. Die Gewichtungen sind Parameter, die im Zuge des „Maschinenlernens“ angepasst werden können. [Quelle: Wikipedia / „Künstliches Neuron“]
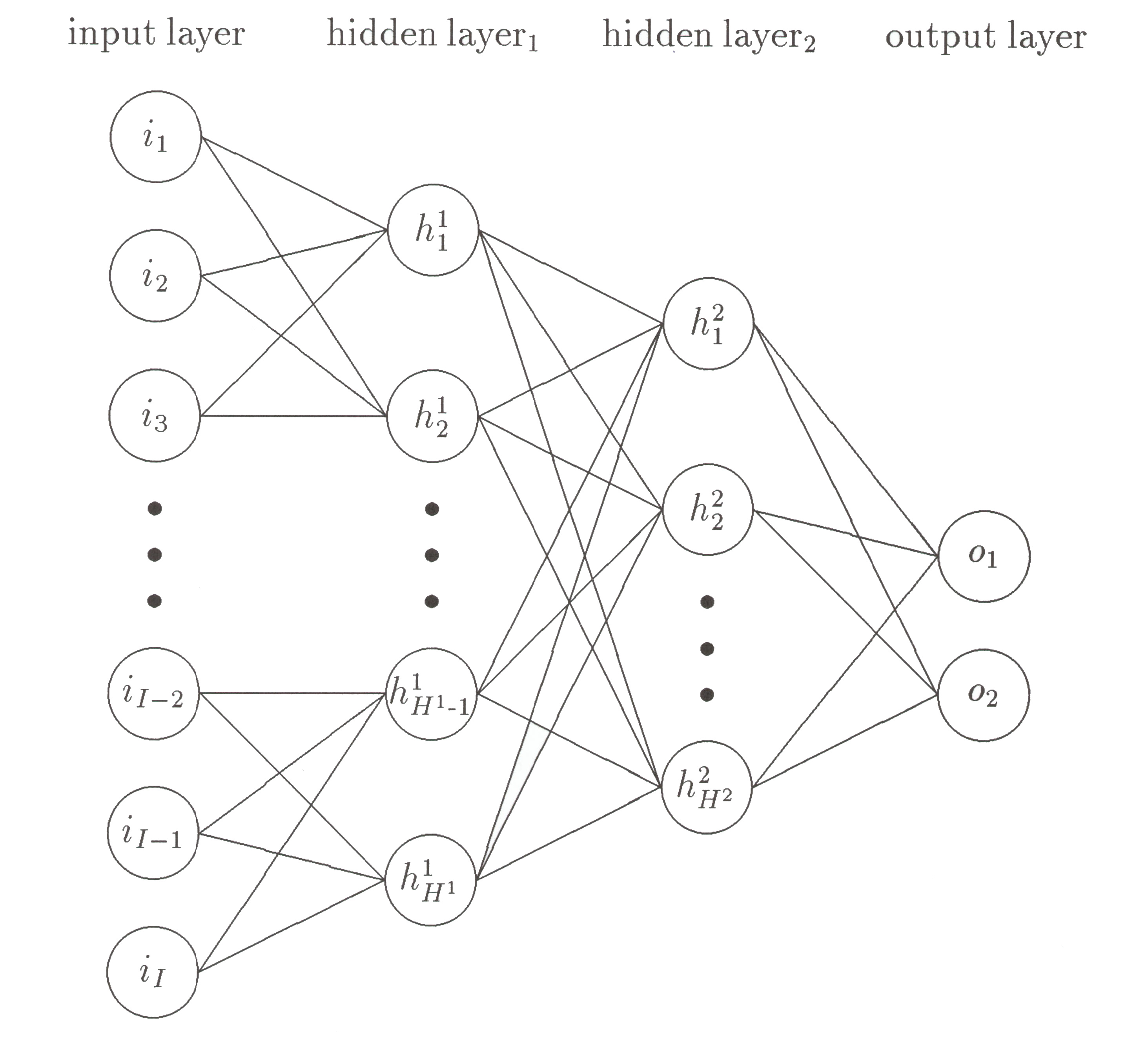
Abbildung 2: Die Arbeitsweise des Gehirns simuliert KI auch dadurch, dass die in Abbildung 1 genannten Berechnungen in mehreren Schichten erfolgen. Die erste Schicht empfängt den Input (z.B. Texte, Bilder, Daten), die letzte Schicht liefert den Output. Dabei wird der Output selten als „Ja“ / „Nein“-Aussagen formuliert („X ist der richtige Entscheider für diesen Vorschlag“), sondern eher als Wahrscheinlichkeiten („X ist mit 82% Wahrscheinlichkeit der richtige Entscheider …“). Zwischen den Input- und Output-Schichten liegen oft mehrere „versteckte Schichten“ („hidden layer“). Dieses Konzept ermöglicht es der KI, eine komplexe Aufgabe (z.B. ein Gesicht zu erkennen) zunächst in kleinste Teilaufgaben zu zerlegen und dann die Teillösungen von Ebene zu Ebene auf höheren Abstraktionsebenen zusammenzufügen, bis am Ende Wahrscheinlichkeiten für die Gesamtlösung angegeben werden können. [Quelle: „A Hybrid Statistical and Neural Network Classification System for Tumour Nuclei“, M. Walla, 1994]
Auch Maschinen müssen zum Lernen in die Schule gehen: Künstliche neuronale Netze benötigen Input (Eingabedaten) und Training. Dafür gibt es zwei Verfahren:
1. Das erste Verfahren („überwachtes Lernen“) wird verwendet, wenn es darum geht, einem Input den richtigen Output zuzuordnen – etwa einem Verbesserungsvorschlag die sachliche Klassifikation oder den zuständigen Gutachter. Voraussetzung ist, dass eine große Anzahl von Beispielen mit bekanntem Ergebnis zur Verfügung steht, mit denen das Rechenprogramm (= künstliches neuronales Netz) in der Trainingsphase gefüttert werden kann. Nach der Trainingsphase sollte das Rechenprogramm dann in der Lage sein, einem neuen (bislang gänzlich unbekannten) Input den richtigen Output zuzuordnen.
- Die Güte bzw. Qualität der so erzeugten „künstlichen Intelligenz“ hängt u.a. davon ab, inwieweit die verfügbaren Beispiele, die Größe und der Aufbau des künstlichen neuronalen Netzes sowie der Aufwand für das Anlernen der Komplexität der gestellten Aufgabe entsprechen. Es ist leicht nachzuvollziehen: Einfache Aufgaben erfordern weniger Beispiele und Aufwand als komplexe Fragestellungen – wie beim menschlichen Lernen auch. Welche Folgen es haben kann, wenn Beispielmenge und Aufgabe nicht gut zusammenpassen, schildert übrigens ein Artikel der SZ vom 10.07.2020.
- Im weiteren Verlauf kann ein künstliches neuronales Netz üblicherweise nicht selbständig feststellen, ob die Bearbeitung bisher unbekannten Inputs „richtig“ oder „falsch“ war (= „Erfolg“ oder „Misserfolg“ hatte). Oft kann aber ein Rückkanal (über Sensoren oder anderweitig gewonnene Daten) dazu beitragen, die Güte der eigenen Entscheidungen zu erkennen und so das „Lernen“ automatisiert fortzusetzen und kontinuierlich besser zu werden.

Abbildung 3: Nach der Trainingsphase per „überwachtem Lernen“ hat das künstliche neuronale Netz gelernt, verschiedene Arten von Krebszellen zu unterscheiden. Entgegen dem Augenschein handelt es sich jeweils auf der rechten und auf der linken Seite um die gleiche Art von Zellen. Erfahrene Ärzte erkennen solche Unterschiede eher intuitiv, können aber kaum explizit beschreiben, woran genau. [Quelle: „A Hybrid Statistical and Neural Network Classification System for Tumour Nuclei“, M. Walla, 1994]
2. Beim zweiten Verfahren („nicht-überwachtes Lernen“) untersucht das Rechenprogramm die eingegebenen Daten auf innere Zusammenhänge und erkennt dabei vorhandene Muster – etwa Clusterstrukturen in großen Ideensammlungen (siehe Abbildung 10). Zuweilen reichen überraschend wenige (einige Hundert) Input-Daten aus, bis KI die wesentlichen Strukturmerkmale „erkannt“ hat. Noch mehr Input macht dann das Ergebnis (den Output) zwar deutlicher, fügt aber keine neuen Erkenntnisse zur eigentlichen Struktur hinzu.
Wie bereits oben angedeutet, wird ein künstliches neuronales Netz dadurch aufgebaut, dass die Parameter während der Trainingsphase so lange geändert werden, bis die Gesamtdifferenz zwischen tatsächlichem Output und erwünschtem Output möglichst minimal ist. Beim „nicht-überwachten Lernen“ entspricht die Differenz den Abweichungen zwischen den erkannten Klassen und den vorliegenden zu klassifizierenden Objekten, z.B. ausgedrückt durch das am wenigsten in eine Klasse passende Objekt.
Den Unterschied zwischen „überwachtem Lernen“ und „nicht-überwachtem Lernen“ kann man vereinfacht so beschreiben:
- Stellen Sie sich einen Obstkorb mit vielen Früchten verschiedener Sorten vor.
- Beim „überwachten Lernen“ würde man von jeder Obstsorte eine Auswahl an Bildern mit den richtig zugeordneten Namen als Input geben. Das Rechenprogramm passt die Parameter so an, dass die vom Rechenprogramm ermittelten Namen für diese Früchte möglichst wenig von den zuvor zugeordneten Namen abweichen. Anschließend wendet man das Rechenprogramm auf andere Bilder der Obstsorten an und erhält als Output einen Wahrscheinlichkeitswert, mit dem es sich um eine bestimmte Sorte handelt. Es ist klar, dass ein Rechenprogramm nicht gelernt haben kann, Heidelbeeren und Erdbeeren den richtigen Namen zuzuordnen, wenn man ihm zuvor nur Bilder von Äpfeln und Birnen mit deren zugeordneten Namen gezeigt hat.
- Beim „nicht-überwachten Lernen“ zeigt man dem Rechenprogramm hingegen nur die verschiedenen Früchte – ohne dass vorab „richtige“ Ergebnisse vorliegen. Das Rechenprogramm prüft dann die Ähnlichkeit bzw. Unterschiedlichkeit verschiedener Früchte und teilt sie durch sukzessive Veränderungen der Parameter in verschiedene Klassen ein: Passt eine Mandarine noch in die Klasse, in die sonst Orangen einsortiert wurden oder muss noch weiter differenziert und eine eigene Klasse geschaffen werden, um das Gesamtergebnis zu verbessern? Die beiden Extreme, jede Frucht jeweils in seine eigene Klasse oder alle Früchte zusammen in eine einzige Klasse einzuordnen, würden zu deutlich höheren Differenzen führen, als die am Ende vom Rechenprogramm erzeugte Klassifizierung. Im Ergebnis macht das Rechenprogramm Aussagen dazu, mit welcher Wahrscheinlichkeit zwei Früchte in die gleiche Klasse gehören (also sehr ähnlich sind) oder verschiedenen Klassen angehören – es würde aber keine „Namen“ für diese ermittelten Klassen vorschlagen können.
Was der Anpassungsprozess von Parametern mit dem Gewusel von Ameisen zu tun hat, ist in einem Artikel der SZ vom 20.06.2020 beschrieben.
Nun noch zu zwei ergänzenden Methoden
Für Anwendungen von KI im Ideenmanagement sind die ergänzenden Fähigkeiten, Wissen in Sinnstrukturen erfassen zu können und Sprache zu beherrschen am wichtigsten – daher gehen wir hier noch kurz auf zwei entsprechende Methoden ein.
„Wissen in Sinnstrukturen“ entsteht, wenn neben den Daten bzw. Begriffen auch ihre Beziehungen untereinander und zugehörige Attribute gespeichert werden. Das kann über Wissensdatenbanken erreicht werden: sogenannte „Knowledge Graphs“ helfen dabei, sichere Informationen strukturiert abzulegen und Sinn- bzw. Bedeutungszusammenhänge maschinell nutzbar zu machen.
- Beispielsweise hat das Wort „Tor“ für einen Fußballer eine andere Bedeutung als für einen Garagenbauer – und im Sinne von „Narr“ nochmals ein völlig andere. In einem übergreifenden Knowledge Graph käme das Wort „Tor“ mehrfach vor und wäre dann mit den jeweils passenden Bedeutungen verknüpft.
- Für spezielle Anwendungen ist häufig nur ein Teil der möglichen Bedeutungen und Beziehungen relevant. Würde etwa ein Unternehmen für Garagenbau seinen eigenen „Enterprise Knowledge Graph“ aufbauen, müssten dort kaum Bezüge zu Begriffen wie „Strafraum“ oder „Narrenkappe“ hergestellt werden – wohl aber sehr enge Bezüge zu „Antrieb“ oder „Fernsteuerung“.
- Weil zwei Worte in dem einen Unternehmen einen sehr engen Bedeutungszusammenhang haben können, in einem anderen aber einen nur sehr geringen oder auch gar keinen, unterscheiden sich Knowledge Graphen von Unternehmen zu Unternehmen (was eben zu einem „Enterprise Knowledge Graph“ führt).
- Das interne Adressbuch könnte als erster und einfachster Ausgangspunkt für einen „Enterprise Knowledge Graph“ dienen, der dann z.B. um Produkte, Standorte, Projekte und vieles mehr ergänzt wird. Damit wird auch deutlich: einen Knowledge Graphen zu erstellen, erfordert viel Arbeit – und er ist nie fertig.
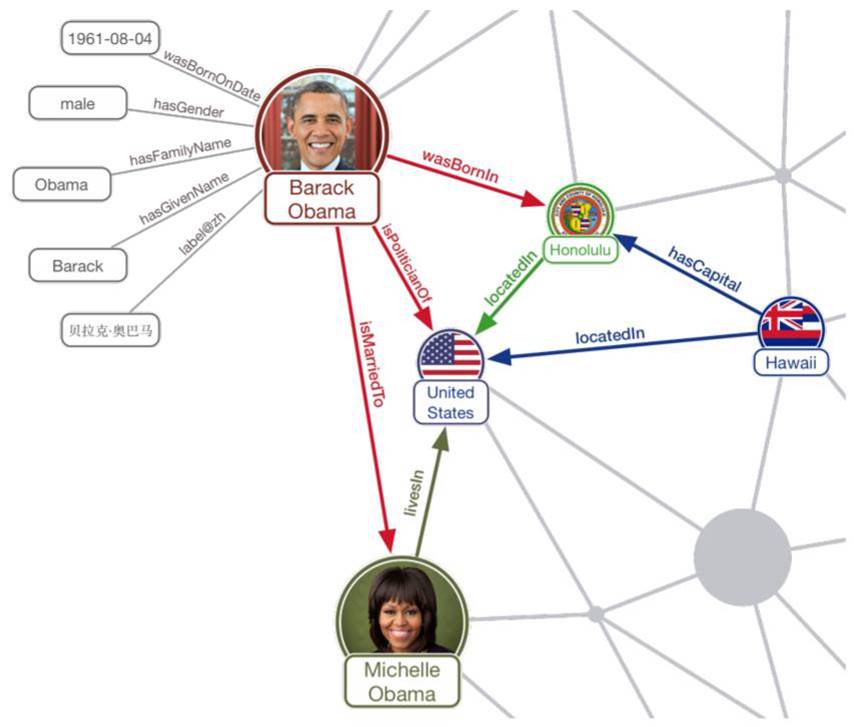
Abbildung 4: Auszug aus einem möglichen Knowledge Graph [Quelle: „Fake News Detection via NLP is Vulnerable to Adversarial Attacks“; Zhixuan Zhou, Huankang Guan, Meghana Moorthy Bhat and Justin Hsu]
Die „Beherrschung von Sprache“ spielt nicht nur im Zusammenspiel von Maschinen bzw. Computern mit Menschen eine große Rolle, sondern auch für die Nutzbarmachung der in schriftlichen und digitalen Dokumenten enthaltenen Informationen. Die Maschine soll „intelligent“ genug sein, sowohl Informationen durch Lesen oder Zuhören aufnehmen, als auch sich durch Schreiben oder Sprechen mitteilen zu können. „Natural Language Processing“ verwendet hierfür neben künstlichen neuronalen Netzen und Knowledge Graphen verschiedene Verfahren der Computerlinguistik.
Linguistische Verfahren ermöglichen etwa, Worte auf ihre Grundformen zurückzuführen (lief – laufen, verspielt – spielen, Tiere – Tier), zusammengesetzte Mehrwortbegriffe zu zerlegen (Großbriefsortieranlage = Groß, Brief, Sortieranlage) oder Eigennamen und geographische Bezeichnungen zu erkennen.
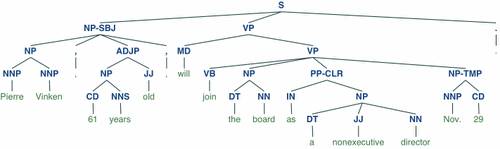
Abbildung 5: Beispiel für eine hierarchische Zergliederung eines Textes (sogenannter „Syntaxbaum“ oder „Ableitungsbaum“), die Voraussetzung für maschinelle Weiterverarbeitung in der KI ist. [Quelle: https://nltk.org]
Die folgende Tabelle veranschaulicht einige Analogien zwischen menschlicher und künstlicher Intelligenz:
|
Menschliche Intelligenz |
„Künstliche Intelligenz“ |
|
Gehirnzellen verknüpfen sich zu biologischen neuronalen Netzen |
„Künstliche neuronale Netze“ werden zuerst gestaltet und dann trainiert |
|
Lernen am Beispiel, aus Erfahrung |
„Machine Learning“ |
|
Strukturiertes Wissen |
„Knowledge Graph“ |
|
Texte verstehen, Texte herstellen |
„Natural Language Processing“ |
|
Sinne helfen zusätzlich bei der Beurteilung |
Technische „Sensoren“ liefern Daten |
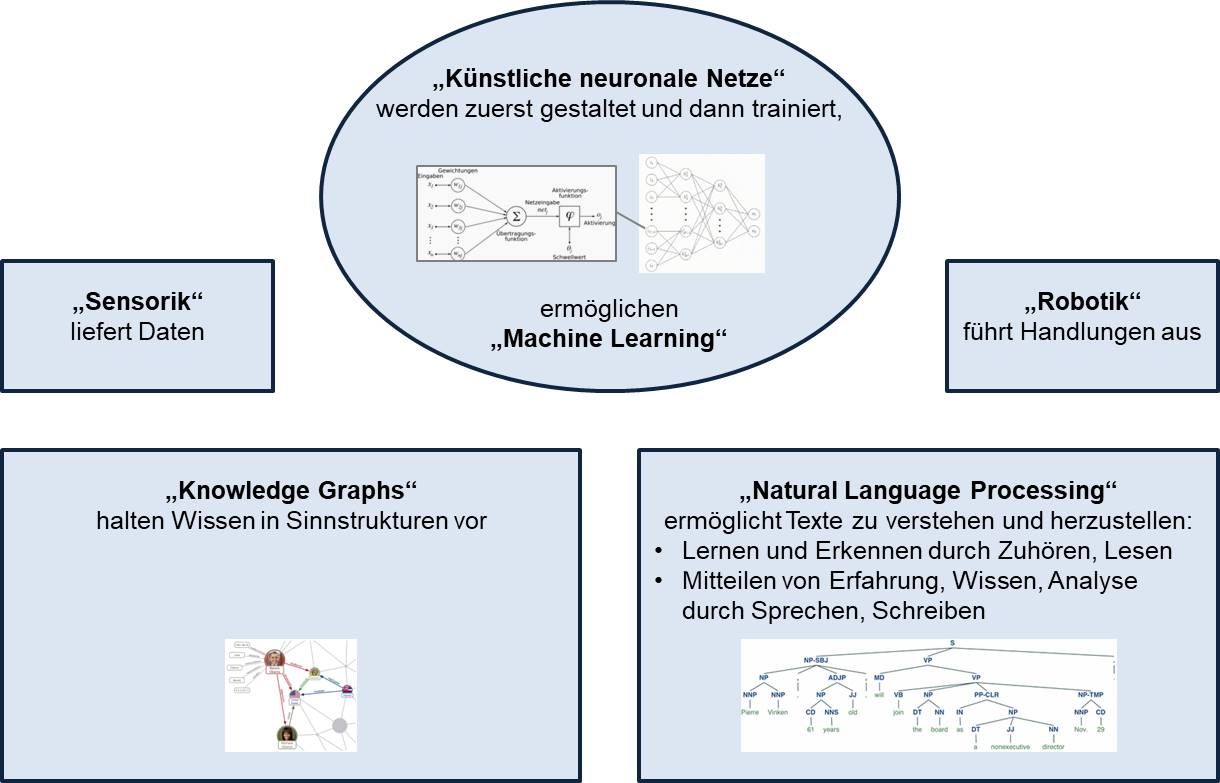
Abbildung 6: KI entfaltet ihr Potential durch die Kombination von künstlichen neuronalen Netzen mit weiteren Methoden und Tools (von denen hier nur eine Auswahl genannt ist).
KI für das Ideenmanagement
Stand der Technik: Künstliche Intelligenz wird bereits für verschiedene Aufgaben im Ideenmanagement verwendet – zuweilen, ohne dass sich der Nutzer dessen bewusst ist.
So bieten erste Unternehmen die Möglichkeit der Spracheingabe für Ideen, indem sie sich die KI von „Alexa Skills“ zunutze machen. Diese Funktion ist vor allem für Einreicher interessant, die wenig Möglichkeiten (oder Bereitschaft) zum Schreiben haben. Sie senkt die Schwelle, einen Vorschlag überhaupt einzureichen und trägt zur Entlastung von Führungskräften bei, die sonst um Hilfe beim Aufschreiben von Ideen gebeten worden wären.
Beispiel Viessmann Climate Solutions SE: „Alexa“ ist der Cloud-basierte Sprachdienst von Amazon, verfügbar auf Amazon-Geräten und vielen weiteren Drittanbietern. Das Ideenmanagement von Viessmann greift diese täglich intuitiv genutzte Technologie auf, um Ideen der Mitarbeiter sofort zu erfassen oder zu steuern. Denn nicht alle Ideen entstehen immer direkt am Arbeitsplatz und geraten so unter Umständen sogar in Vergessenheit.
- Bereits nach der Aktivierung des Skills in der Alexa-App kann es losgehen: „Alexa, starte Viessmann-Ideenmanagement“ oder „Alexa, öffne das Viessmann Ideenmanagement“ – und schon erfolgt die freundliche Begrüßung durch Alexa. Alle über Alexa eingereichten Ideen werden aus Sicherheitsgründen zunächst als Entwurf in der Ideenplattform gespeichert und können anschließend entsprechend weiterbearbeitet werden, um so weitere Bilder, Videos oder Dokumente der Idee zusätzlich beizufügen. Wird eine Idee via Alexa eingereicht, erhält das Ideenmanagement zudem eine Information. Bemerkenswert sind hierbei die sekundenschnelle Übertragung und die Genauigkeit der erfolgten Spracheingaben.
- Seitens des Ideenmanagements sind auch weitere Features in Planung wie beispielsweise: “Alexa, wie ist der Stand meiner aktuellen Ideen?” oder “Alexa, ich habe keine Idee – hilf mir.”
- Ziel des zusätzlichen Angebots ist es, die Teilnahme am Ideenmanagement noch einfacher zu machen und alle Mitarbeiter zu motivieren, ihre Ideen einzureichen, denn Kreativität und Erfindergeist sind entscheidende Erfolgsfaktoren.

Abbildung 7: Beispiel der Spracheingabe bei Viessmann. [Quelle: Viessmann Climate Solutions SE]
Chatbots werden bereits seit längerem von vielen Unternehmen für die unterschiedlichsten Kommunikationsaufgaben eingesetzt – mittlerweile auch im Ideenmanagement. Hier sind verschiedene Anwendungen möglich, um Ideenmanager von Routinekommunikation zu entlasten.
In der Kommunikation mit Einreichern könnten Chatbots etwa:
- Auskunft zum Bearbeitungsstand von Ideen geben.
- Fragen zum System beantworten.
- Ideen aktiv abholen und inspirierende Fragen stellen.
- auf Unvollständigkeiten und Weiterentwicklungsbedarfe/-möglichkeiten hinweisen.
In der Kommunikation mit Gutachtern könnten Chatbots etwa auf Fristen hinweisen und (standardisierte) Hilfe anbieten.
Beispiel Continental AG: Ein Chatbot ist im Grunde nichts anderes als eine „selbstlernende FAQ-Liste“. Im Unterschied zu einer klassischen FAQ-Liste, in der ein Nutzer in der Liste die zu seinem Anliegen passende Frage erst suchen und finden muss, kann er seine Frage dem Chatbot in eigenen Worten direkt stellen. Es ist dann Aufgabe des Chatbots, zu erkennen, welche der Fragen gemeint sein könnte, für die er Antworten bereithält.
- In einem ersten Schritt haben die Ideenmanager bei Continental daher in einem Workshop Fragen gesammelt, mit denen sich typischerweise Einreicher an das Ideenmanagement wenden. Jeder Frage wurde in einer Excel-Tabelle eine Antwort zugeordnet.

Abbildung 8: Auszug der Excel-Datei, auf der der Chatbot bei Continental basiert. [Quelle: Continental AG]
- Der Übergang von Excel zum Chatbot erfolgte, indem die Chatbot-Software aus den Fragen die Füllwörter mit Hilfe von KI-Algorithmen herausfilterte. Den verbleibenden Schlüsselbegriffen blieb die jeweilige Antwort zugeordnet. So entstand eine Liste aus Paaren von Kombinationen von Schlüsselworten in der einen Spalte und von Antworten in der anderen Spalte. Der gleiche Schlüsselbegriff kann durchaus in mehreren Paaren vorkommen, aber dann in verschiedenen Kombinationen mit anderen Schlüsselbegriffen.
- Gibt ein Nutzer nun eine Frage ein, berechnet der Chatbot, welche Kombination von Schlüsselbegriffen am wahrscheinlichsten zu den eingegebenen Worten der Frage passt und gibt die entsprechende Antwort aus. Das ist bei Continental auch per Sprachausgabe möglich.
- Um „lernen“ zu können, bittet der Chatbot stets um Feedback – etwa indem er fragt: „Ist meine Antwort zufriedenstellend?“. Der Nutzer kann dann per Ampel-Klick angeben, ob die Antwort passte (grün), nur teilweise passte (gelb) oder gar nicht passte (rot).
- Klickt der Nutzer „gelb“ an, dann fragt der Chatbot nach: „Was fehlt Dir?“. Anhand der Eingabe des Nutzers sucht der Chatbot nach besseren Antworten und legt neue Paare von Schlüsselbegriffkombinationen – Antworten an. Auf diese Weise „lernt“ der Chatbot.
- Wenn der Nutzer „rot“ anklickt, dann entschuldigt sich der Chatbot, dass er nicht weiterhelfen konnte und verweist an das Ideenmanagement. Der Ideenmanager erhält als „Master“ vom Chatbot einen Hinweis mit der Anforderung, die Liste der Schlüsselbegriffkombination-Antwort-Paare zu ergänzen.
- Nicht zuletzt wurde festgelegt, wie sich der Chatbot melden soll, wenn man ihn aufruft (z.B. „Hallo, was kann ich für Dich tun?“), was er sagen soll, wenn man ihm Fragen stellt, die nicht zum Thema passen (z.B. „Wo gibt es Schokolade?“ – „Entschuldigung, diese Frage kann ich nicht beantworten.“), oder wenn völlig unsinnige Eingaben gemacht werden (z.B. „Dnkril zasj“ – „Entschuldigung, diese Frage verstehe ich nicht.“).
- Der Chatbot ist mit einem eigenen Symbol von jeder Seite des Ideenmanagement-Portals aus aufrufbar (wobei die Chatbot-Software unabhängig von der Ideenmanagement-Software ist). Dabei bleibt das Chatbot-Symbol stets an der gleichen Stelle des Bildschirms, unabhängig davon, wohin in der Ideenmanagement-Software gescrollt wird.
Abbildung 9: Symbol für den Chatbot „CIMI“ bei Continental im Entwurfsstadium. [Quelle: Continental AG]
- Derzeit befindet sich der Chatbot bei Continental in einer auf ein Jahr angelegten Lern- und Testphase in englischer Sprache. Danach sind Übersetzungen in alle 26 Landessprachen geplant, die an den Standorten von Continental gesprochen werden. So wird der Chatbot in jedem dieser Länder in allen Sprachen genutzt werden können.
- Parallel laufen die Vorbereitungen zur Bekanntmachung des Chatbots – etwa, indem ein passender Name („CIMI“ – angelehnt an Continental IdeenManagement) vergeben wird und Werbeposter entworfen werden.
Manche Unternehmen nutzen KI-basierte Übersetzungen, um den Best Practice Transfer in andere Länder zu unterstützen. Allein schon aus Gründen des Datenschutzes, aber auch zur besseren Berücksichtigung der einschlägigen Terminologie empfiehlt sich der Einsatz von firmenspezifischen Übersetzungsprogrammen auf der Grundlage des jeweiligen Enterprise Knowledge Graphs anstelle des Google Translators.
Aktuelle Entwicklungen: Die Arbeit an KI-Lösungen ist dort besonders aussichtsreich, wo einerseits ausreichend große Datenmengen für das Training zur Verfügung stehen und andererseits ein nennenswerter Nutzeneffekt (Zeiteinsparung, Entlastung) zu erwarten ist.
Ein Beispiel ist die Entwicklung einer Ideensuche, bei der Ähnlichkeiten und Dubletten unabhängig von Schreibfehlern bzw. Schreibvarianten mit Hilfe von KI erkannt werden. Diese Funktion ist für fast alle Akteure im Ideenmanagement interessant, z.B. Einreicher: „Ist meine Idee neu? Worauf kann ich ggf. weiter aufbauen?“; Ideenmanager: „Ist die Idee eine Dublette (Formalprüfung)?“; Management / Gutachter: „Welche Ideen gab es schon zum Thema XYZ (inkl. abgelehnte)?“ Entsprechende Lösungen sind für andere Anwendungen (u.a. im Innovationsmanagement) in verschiedenen Unternehmen bereits im Einsatz. Was bereits möglich ist, beschreibt z.B. ein Video zu SAP HANA ab 1m:25s.
Des Weiteren wäre es in vielen Unternehmen wünschenswert, das Management der Ideen dadurch zu erleichtern, dass die Zuordnung von Klassifikationen oder von Gutachtern bzw. Entscheidern automatisiert erfolgt. Selbst wenn im „Vorgesetztenmodell“ stets die Führungskraft „automatisch“ zuständig wird, steht diese dann häufig vor dem Problem, einen geeigneten Experten für Inhalte zu finden, zu denen ihr selbst die Fachkompetenz fehlt.
Beispiel Deutsche Post DHL Group: Entsprechende Möglichkeiten für eine „Entscheidersuche“ werden derzeit bei der Deutschen Post DHL Group getestet. Da die Mitarbeiter jährlich etwa 60.000 Ideen einreichen, steht ein ausreichend großer Datenpool für das „Training“ der KI bereit.
- In einem ersten Test wurde mit „word counting“ eine relativ einfache KI-Methode verwendet. Das „Training“ erfolgte mit 9.000 Vorschlägen, denen Themencluster und der jeweils richtige Entscheider zugeordnet waren. Anschließend wurde der „Lerneffekt“ an 1.000 anderen Dokumenten überprüft – es ergab sich jedoch kein nachvollziehbares Treffermuster.
- Im zweiten Test kamen daher aufwändigere linguistische Verfahren des „Natural Language Processing“ zum Einsatz, die mit 1.500 Vorschlägen „trainiert“ wurden (wieder mit jeweils zugeordneten Themenclustern und Entscheidern). Der „Lerneffekt“ wurde mit 138 Dokumenten überprüft. Die Zuordnung der Dokumente zu Entscheidern erfolgte in einer Prioritätenliste (Rang 1 bis 5 nach Größe der Wahrscheinlichkeit, dass der jeweilige Entscheider der richtige ist). In knapp der Hälfte der Fälle war der richtige Entscheider in den Prioritäten 1 bis 5 enthalten, in knapp einem Viertel stand er sogar auf Platz 1.
- In den beiden ersten Tests waren allerdings nur die Beschreibungen im Eingabefeld berücksichtigt worden. Bei vielen Ideen befindet sich der größte und inhaltlich relevantere Text jedoch in den Anlagen. Daher sollen im nächsten Schritt die Anlagen in die Textanalyse mit einbezogen werden. Eine noch weitergehende Verbesserung könnte zudem erzielt werden, wenn das Training der künstlichen neuronalen Netze (für das Natural Language Processing) mit dem Enterprise Knowledge Graph (speziell zum Wissen über die Organisationsstruktur) verknüpft würde. Auch die Ideenmanager orientieren sich bei der Zuordnung von Entscheidern ja nicht nur an den Inhalten der Vorschläge und ihren bisherigen Erfahrungen, sondern haben das Organigramm ihres Unternehmens „im Hinterkopf“.
Ein drittes Entwicklungsfeld betrifft die Ermittlung von Themenclustern im Datenpool der Ideen sowie deren zeitliche Veränderungen („Trendradar“). Mögliche Anwendungen wären u.a.:
- Erkennung und Lokalisierung bisher unbekannter Schwerpunktthemen. Anhand der Beschreibungen des „Ist-Zustands“ in Vorschlägen könnte eine auf „von unten“ beigesteuerten Informationen beruhende Darstellung der Wirklichkeit des Unternehmens erstellt werden, mit der andere Versuche, das Geschehen im Unternehmen zu beschreiben (z.B. Prozessbeschreibungen, Betriebshandbücher, Qualitätsmanagementhandbücher, Kennzahlen-Cockpits) ergänzt werden.
- Identifikation von Problemfeldern, für die noch kreative Lösungen gesucht werden (z.B. häufig von Vorschlägen adressierte Themen, bei denen noch keine Idee umgesetzt wurde).
- Ableitung von Informations- und Qualifikationsmaßnahmen: Aus den Inhalten der abgelehnten Vorschläge und den Ablehnungsgründen könnten je nach Begründung Maßnahmen abgeleitet werden. Bei Ablehnung aufgrund mangelnder Priorität könnten Mitarbeiter über Prioritäten und dahinterstehende Unternehmensziele / -strategien gezielt informiert werden. Oder das Top-Management könnte darauf hingewiesen werden, welche Themen mangels Priorität drohen, „unter die Räder zu geraten“ (aber aus Sicht der Mitarbeiter wichtig wären). Ablehnungen aufgrund sachlicher Gegebenheiten geben Anlässe für Qualifizierungsmaßnahmen zu Themen, bei denen Mitarbeitern offensichtlich besonders häufig Informationen, Kenntnisse und/oder Verständnis zu Hintergründen, Zusammenhängen oder konkreten Zahlen, Daten, Fakten fehlen (mit deren Kenntnis sie die Vorschläge nicht eingereicht hätten).
- Intelligente Verknüpfungen von Ideen.
- Vernetzung zwischen Ideen/gebern bzw. Wissen/strägern und Förderung der Kollaboration.
- Identifikation von Personen mit bestimmten Eigenschaften oder Potentialen: Sofern Anforderungen des Daten- und Personenschutzes dabei gewahrt bleiben, könnten Personen anhand des Verhaltens als Einreicher, Bearbeiter oder Kommentator (z.B. Votings in Ideenforen) identifiziert werden als
- Experten (mit hoher Beurteilungskompetenz) zu bestimmten Themen – z.B. aufgrund schneller Entscheidungsfähigkeit, hoher „Treffer“quote der Votings (d.h. Vorschläge, die positive Votes dieser Person erhielten, sind tatsächlich oft erfolgreich), o.ä.
- Innovatoren mit großer Kreativität in bestimmten Themenbereichen.
- Teamplayer / Networker, die sich überdurchschnittlich oft gemeinsam mit anderen engagieren.
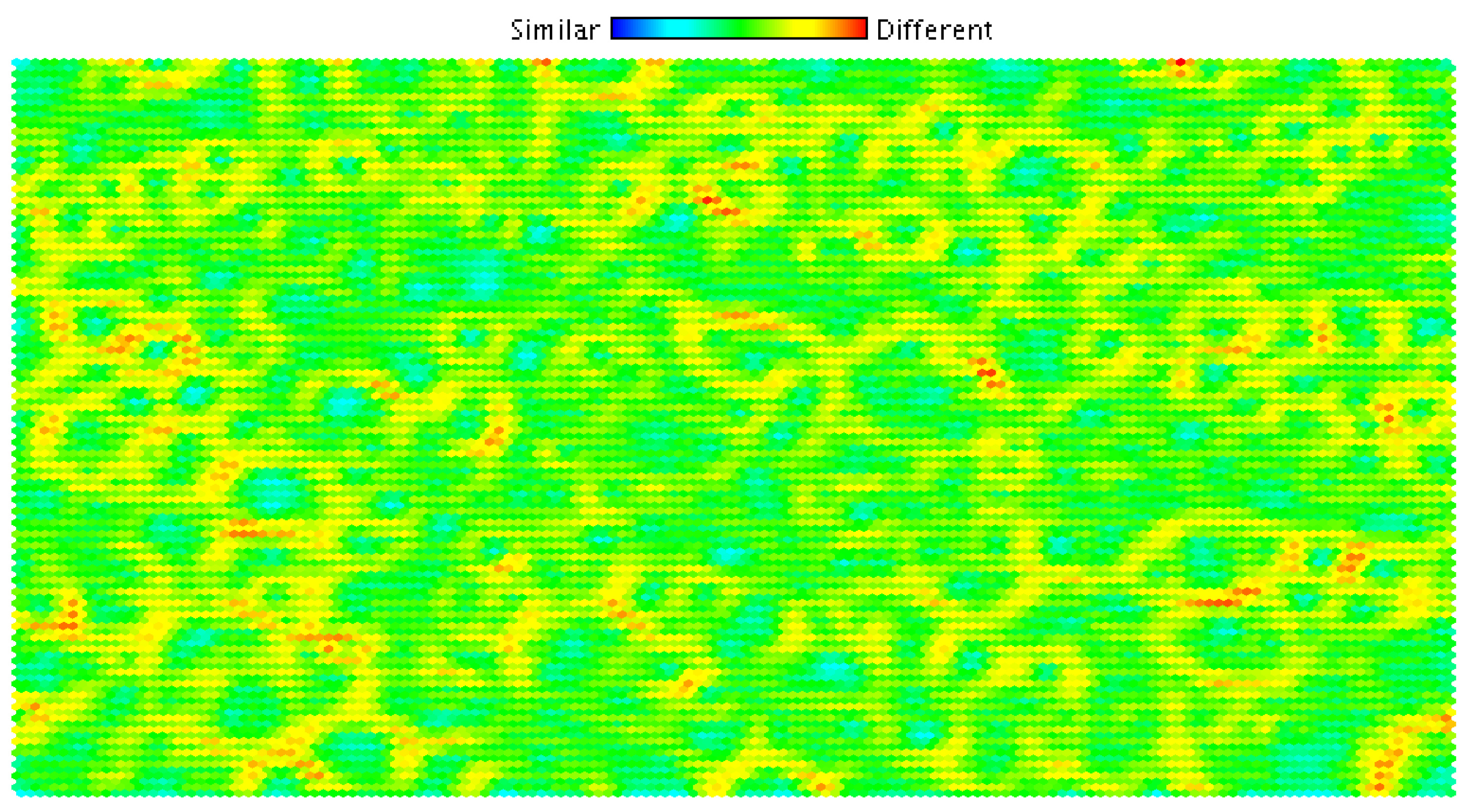
Abbildung 10: Beispiel für eine „selbstorganisierende Karte“ (als Form des Outputs für die erkannte Struktur) zur Erkundung einer Ideenmenge. Bereiche mit sehr ähnlichen Ideen sind blau, Bereiche mit stark unterschiedlichen Ideen rot markiert. Mit solchen Verfahren könnten Kategorisierungen erzeugt werden, die generisch aus den gesammelten Daten selbst entstehen – während die bisher verwendeten Klassifikationen oder Zuordnungen zu einer Prozesslandschaft den Inhalten von außen vorgegeben und aufgeprägt werden. Es entstünde eine Art auf Ideen bezogener „Enterprise Knowledge Chart“, in der semantische Knoten visualisiert werden können. [Quelle: „Unterstützung bei der Bewertung von Ideen durch Neuronale Netze“, Sandra Bracholdt, Mittweida, 2015]
Weitere Visionen: Eine Reihe weiterer Anwendungen ist zwar prinzipiell vorstellbar, vorerst bleibt aber offen, ob und wann sie realisiert werden.
- Gutachter unterstützen: z.B. passende kontextspezifische Bewertungskriterien / Entscheidungshilfen je nach Thema des Vorschlags anbieten.
- Erkennung von Potential-Ideen: Ideen mit hohen Erfolgsaussichten, hohen Nutzenpotentialen, hohem Innovationsgehalt. Ggf. Abgleich mit Trend-Themen und Einschätzung im Kontext vorhandener Prioritäten.
- (Inhaltliche) Vollständigkeit eines Vorschlags prüfen, Reifegrad feststellen.
Nutzen Sie die Potentiale von KI für Ihr Ideenmanagement! Fordern Sie Lösungen von Ihrem Software-Hersteller!
Hinweise auf Autoren und Quellen:
Die Inhalte dieses Beitrags geben Ergebnisse des Erfahrungsaustauschs im Expertenkreis „Globales Ideenmanagement“ wieder. Die Erläuterungen zur „KI für Laien“ beruhen ganz wesentlich auf Input von Martin Walla. Die Entwicklungen für eine KI-basierte Entscheidersuche bei der Deutschen Post DHL beschrieb Thomas Dierker (Leiter Ideenmanagement Konzern Deutsche Post DHL). Die Praxisbeispiele wurden beigesteuert von Peter Becker (Leiter Ideenmanagement Viessmann Climate Solutions SE) und Matthias Nehrhoff (Leiter Ideenmanagement Konzern Continental AG).
Die Abbildungen stammen aus folgenden Quellen:
1., 6.: Wikipedia / „Künstliches Neuron“
2., 3., 6: „A Hybrid Statistical and Neural Network Classification System for Tumour Nuclei“, M. Walla , 1994
4., 6.: „Fake News Detection via NLP is Vulnerable to Adversarial Attacks“; Zhixuan Zhou, Huankang Guan, Meghana Moorthy Bhat and Justin Hsu (https://www.researchgate.net/publication/330701046_Fake_News_Detection_via_NLP_is_Vulnerable_to_Adversarial_Attacks)
5., 6.: https://nltk.org
7. Viessmann Climate Solutions SE
8., 9.: Continental AG
10.: „Unterstützung bei der Bewertung von Ideen durch Neuronale Netze“, Sandra Bracholdt, Mittweida, 2015
Ein nach Stichworten sortiertes Verzeichnis mit Links auf alle bisher erschienenen Beiträge im Blog zum Ideenmanagement finden Sie in diesem Register.
Alle Erwähnungen von Produkten und Unternehmen sind redaktioneller Natur und wurden nicht bezahlt.


